Ibercivis nació en 2008 como un proyecto de colaboración entre los distintos centros organizadores, una especie de pacto entre caballeros en el que cada institución apoyaba con esfuerzo para sacar el proyecto BOINC adelante. Por dotar a la iniciativa de cierta independencia, mayor visibilidad, eficiencia, agilidad y mejor operabilidad se decidió crear una Fundación privada sin animo de lucro. Fue creada en Noviembre de 2011 en Madrid pero por temas burocráticos no pudimos empezar a trabajar hasta Octubre de 2012.
La Fundación tiene como objetivos continuar con la labor de colaboración e integración ciudadana en la investigación científica y realizar actividades de divulgación y formación. Naturalmente, se da continuidad al proyecto de computación voluntaria que aprovecha los ciclos ociosos de los ordenadores de sobremesa de los voluntarios para realizar simulaciones numéricas de los grupos de investigación. Además de construir dicha red de computación, realizamos otros experimentos que permiten a la sociedad participar en la investigación a través de sus dispositivos personales y su propia inteligencia. Apuntamos a tres formas de participación y aprovechamiento de los voluntarios: como red de computación (con los ordenadores de sobremesa), como red de sensores (con los teléfonos móviles) o como red de colaboradores (realizando tareas tipo análisis de imágenes). En todo caso, todas las personas pueden aportar y sernos útiles, todas.
España apuesta por la ciencia ciudadana al crear la Fundación Ibercivis, lo que nos coloca en una posición privilegiada para ser referencia internacional en proyectos de investigación que aprovechan los recursos de todos los ciudadanos. Hacemos investigación, promoción, integración y apoyo de iniciativas de ciencia ciudadana, que permiten la participación útil de personas externas a laboratorios en investigaciones de distintas áreas de conocimiento. Contamos con pocos fondos, pero muchas ganas de trabajar y miles de ideas.
Hasta el momento contamos con más de 36.000 voluntarios de los cuales unos 5.000 colaboran de forma estable, desde casi todas las zonas del mundo. Gracias a Ibercivis se fomenta la formación avanzada, se inculcan valores sociales y científicos, se crea una comunidad de personas. Ellos son los actores principales de Ibercivis.
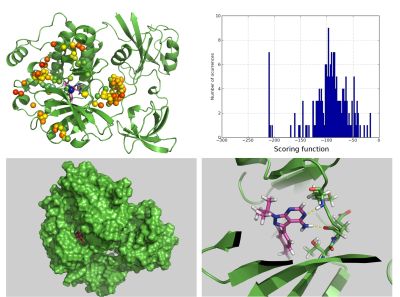
Los otros protagonistas son los investigadores. Hemos dado soporte a 16 grupos de investigación, pertenecientes a las entidades fundadoras pero también de otros organismos de investigación nacionales y latinoamericanos. A los grupos de investigadores usuarios de los recursos ciudadanos les facilitamos el acceso a nuevas fuentes de cómputo, nuevas fuentes de datos, a la par que se abren nuevos canales de interacción y divulgación científica.
Contamos con las siguientes entidades fundadoras: el Ministerio de Economía y Competitividad (entonces Ministerio de Ciencia e Innovación), la Universidad de Zaragoza, el CSIC, el CIEMAT, Red.es, la Fundación Zaragoza Ciudad del Conocimiento, el Gobierno de Aragón y la Fundación Ikerbasque.
Además de la Fundación Ibercivis española, Ibercivis también es una iniciativa portuguesa con la participación de las siguientes instituciones: UMIC (Agência para a Sociedade do Conhecimento), Universidad de Coimbra (Centro de Neurociências e Biologia Celular), LIP (Laboratorio de Instrumentação e Física Experimental de Partículas), FCCN (Fundação para a Computação Científica Nacional) y Ciencia Viva (Agência Nacional para a Cultura Científica e Tecnológica).