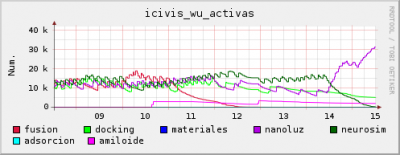
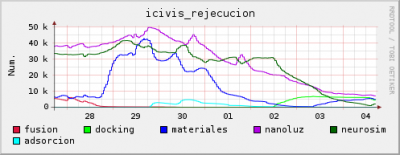
Un usuario tenia sistematicamente mas de 24 horas de CPU todos los dias. Tras examinar su configuracion y solicitarle datos de su maquina, el resto de las herramientas del sistema, incluido ps aux, tambien daban los mismos datos: porcentajes de utilizacion de CPU de hasta el 300%. Al parecer es un problema del nucleo de linux cuando esta a su vez multihilado, multinucleo y preemptivo... es un problema general, pero no demasiado. En Ibercivis, tan solo un una maquina de cada mil muestra "eficiencias" por encima del 100%.
En el caso que nos ocupa, las eficiencias muestreadas durante el mes de concurso han sido, en tanto por uno: 3.1, 3.47, 1.89, 1.73, 2.73. Hemos determinado pues aplicar a esa maquina un factor de correccion de 2.62.
Sí alguno de vosotros podeis reproducir el problema con fiabilidad (no hace falta tener Ibercivis ni BOINC, basta con fijarse en el ps, aunque puede que solo ocurra en procesos multihilo corriendo con un nice alto) nos gustaria tener noticias de ello. Me dicen los de grid que ya hubo un debate parecido cuando el Pentium 4 comenzo a incorporar funcionalidades multihilo.
En cuanto al resto de los concursantes, encontramos que cumplen la normativa, aplicadas las penalizaciones correspondientes. Con ello, el calendario que seguiremos sera publicar mañana las listas -provisionales- de la asignacion de boletos para los sorteos y de los premios directos, y publicar el dia 5 la lista completa de premiados para contactar con ellos. Os recordamos que en los casos de concursos locales hay que certificar la afiliacion.
Actualización: La distribucion preliminar por la ley de hont era erronea en el caso de los dos concursos individuales que la usaban y ha sido sustituida por la -esperamos- correcta. Y en los tres concursos, el orden era exactamente el inverso del especificado en las bases, asi que ha habido que republicar las listas corregidas. Al final de la jornada laboral se comunicará por email a los interesados su rango de numeros.
Explicación: El objetivo de las reglas de los concursos individuales era poder premiar la dedicación pero sin dejar de lado la potencia. Asi la dedicación al concurso, prestando atencion a que las maquinas esten activas, es lo que te da valor para entrar en el corte de sorteo de los diez primeros y una vez ahi el reparto corresponde a la potencia, usease el total de creditos.