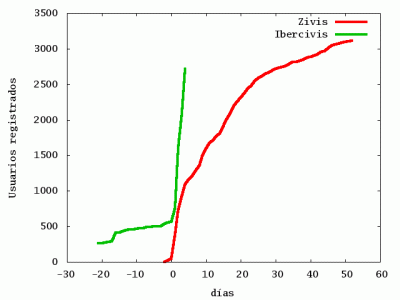
Como dijimos, esta parada hemos hecho mas pruebecicas. Hemos mejorado algun que otro acceso a disco, limpiado un par de atime que podrian molestar en sistemas de ficheros ext3 (alguno lo hemos puesto a noatime, otros a relatime), y refinado el my.conf de la base de datos, y parece que se nota. No obstante estoy aun un poco mosca con el raid de discos. Es un raid 1+0 de cuatro discos, y de alguna manera cuando esta en competicion con todo el httpd y el mysqld en marcha no se comporta como debiera. Ahora mismico, un test de bonnie++ ha escupido
------Sequential Output------ --Sequential Input- --Random-
-Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
94650 57 109599 29 16450 3 28923 15 17693 1 171.9 0
A lo que entiendo, Bonnie llama Output a la escritura en disco e Input a la lectura desde disco. Asi que ya veis que no encaja la cosa: ¡109Mbytes de escritura contra apenas (en el peor de los test que he hecho) 18 MB/sec de lectura!. Una confirmacion independiente la da el correr iostat en paralelo con los tests: se puede ver que durante las escrituras el md0 se sube hasta 115MB/seg, que el rewritting mantiene hasta como mucho 34MB/sec en lectura y en escritura... y que la lectura a secas no consigue levantar mas de esto.
En la misma maquina, con el disco duro raiz, que no esta en el raid, se consigue
------Sequential Output------ --Sequential Input- --Random-
-Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
30007 17 29160 6 15809 2 33730 17 39346 3 117.9 0
En teoria, un 1+0 de cuatro discos deberia ser al menos 2 veces mas rapido en escritura que un disco solo,
y cuatro veces mas rapido en lectura. No cuadran las cuentas. Hay que tener en cuenta que aparte del test los discos llevan un trafico majico en registro/bajada de ibercivis, del orden del megabyte por segundo, y algo menos de la mitad para el raiz. Pero los resultados no parecen cambiar demasiado si paro procesos.
Por comparacion, www.ibercivis.es tiene un solo disco con dos particiones lvm, las cuales ademas estan con el journaling simplificado del ext3, "=writeback". Las dos se ponen tranquilamente con el bonnie por encima de los 50 megabytes/sec tanto en lectura como escritura de bloques. Y el journaling no afecta a la lectura, que es lo que esta fallando.
El primer sospechoso es el layout del Raid, "near=2, far=1", con chunks de 64K. Esto es el default, "n2". Que ya sabia uno que no es tan espectacular en los tests como "f2" pero a fin de cuentas tampoco es el servidor web, asi que la escritura es tan importante o mas que la lectura. Pero ni siquiera el obseso de Makarevitch llega a notar diferencias espectaculares.
Volviendo a mirar el iostat, se ve un detalle que ya noto Samuel el otro dia: al hacer las lecturas, un solo disco se esta comiendo todo el marron de su pareja: mientras sde y sdf van a la par, el sdc se come todo el marron que deberia tener sdd. Si el md da 30MB, 15 vienen de cada par, y del par c/d resulta que 14MB vienen del c. El escaqueado es un hitachi de la ostia que compramos hace poco en sustitucion de un failed, pero tambien el sdf es del mismo modelo y mes, y da el callo como el que mas. ¿No sera que el c se pasa de currar y no le deja al otro?
[EDIT, arivero, jul 10 14:52] Hemos cambiado el cable de alimentacion y el cable SATA, y la velocidad de lectura de sdd ha subido del megabyte rancio hasta los nominales 75MB/sec que se esperan de un 500 Gigas. Conjetura: le faltaban amperios.
Para comprobar los discos una herramienta rapida es, quien lo iba a decir, hdparm -A -C -t -T /dev/sda
Hay quien sugiere desactivar el look-ahead del disco para los RAID. De todas formas hay que tener en cuenta que el propio OS tiene otro read ahead, vease blockdev --getra /dev/md0, que en este caso esta ajustado al doble del readahead de sus componentes, blockdev --getra /dev/sdX. Habria que diseñar probatinas especificas de nuestra carga.
 . Total, que resulta que podemos optimizar las copias a las ramas quitando indices que no van a utilizar y añadiendo indices que sí que pueden necesitar. Es de esta manera como conseguimos listar en menos de cinco minutos las actividades de los ultimos cinco minutos
. Total, que resulta que podemos optimizar las copias a las ramas quitando indices que no van a utilizar y añadiendo indices que sí que pueden necesitar. Es de esta manera como conseguimos listar en menos de cinco minutos las actividades de los ultimos cinco minutos  . Otro dia os contare por qué no conseguimos listar las coordenadas de los usarios a la misma velocidad.
. Otro dia os contare por qué no conseguimos listar las coordenadas de los usarios a la misma velocidad.