Un truco interesante de mysql, que aun no hemos implementado pero que lo vamos a pensar.
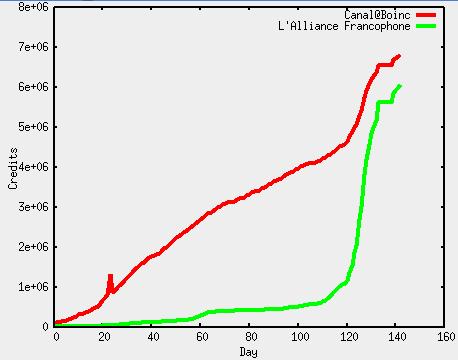
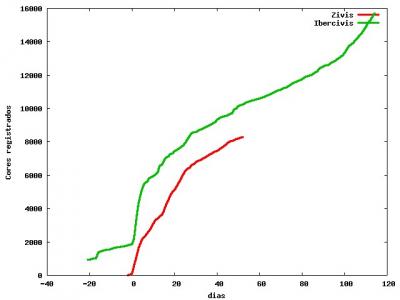
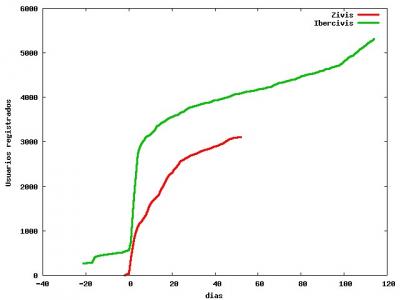
Ahora mismo, ya lo he dicho antes, el esqueleto de ibercivis son seis maquinas: cuatro de ellas forman un circulo mysql db0, db1, db2, db3 y vuelta a db0 en cuanto a actualizaciones de la base de datos; y otras dos forman una rama dbweb y dbusers donde se copian los datos que son de solo lectura en las consultas via web. La rama sale de una de las del circulo, digamos db0.
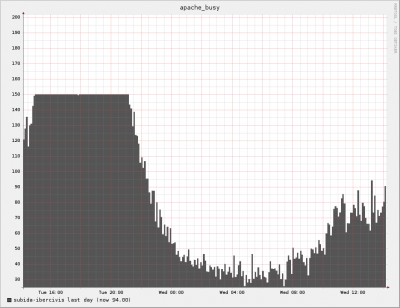
Una de las maquinas del circulo no esta propiamente en los centros de los investigadores sino en instalaciones de rediris. De hecho nos pillo el apagon de Telvent el lunes pasado. Al estar lejos de la tentacion de los investigadores es pues un buen candidato para todas las tareas de gestion: backup de la base de datos, purgado de workunits antiguas y esas cosas. El problema es que estas tareas crean Locks en la base de datos y por tanto retrasan la propagacion a traves del circulo; por ello nuestra solucion y supongo que la de casi todo el mundo es repartirse estas tareas entre todas las maquinas dbN.
Pues bien, resulta que ya va para dos años que se sabe una forma de tener dos masters con un solo esclavo en MySql. Tan solo he encontrado en la web un documento que lo explica: http://www.shinguz.ch/MySQL/mm-single-slave-repl.pdf El truco esta en que en la maquina esclavo deben correr dos esclavos: el de verdad, que apunta al master que mas trafico tenga, y el secundario, que apunta al otro master y ¡no tiene tablas propias, sino federadas!
El resto del truco es tan trivial que ya ni lo dicen: tan solo uno de los masters, el que va al esclavo principal, debe tener activado el log-slave-updates, pues de lo contrario al volver a unirse los flujos se duplicarian todos los updates que vienen del aguas arriba. Tambien hay que tener en cuenta el server_id y sospecho que otros detallitos por investigar. Pero la solucion es interesante. El "circulo" final tendria las replicaciones:
| db0------>db1 | db1-------->db2 | db2----->db3 | db3---->db0’ | db0’ ---fed--->db0 |
| | db2------------------------------------------------->db0 |
y podriamos hacer consultas "bloqueantes" en db3 sin que se interrumpiera la propagacion de cambios. No asi en db0’, pues no es mas que un acceso disfrazado a db0.
¿por qué no se explica esto en el manual? Supongo que no es porque no funcione, sino porque la posibilidad de paradas de la circulación aumenta mucho: db3 podria escribir sobre fichas que luego no existen en db0 porque ya ha llegado alli una señal de borrado que en db3 estaba atascada, o cosas asi. En tal caso, la replicacion se para y el sysadmin se gana el sueldo. Pero si uno tiene claro que db3 solo va a escribir o borrar cosas que no van a desaparecer por culpa de otro nodo, (o al menos no en las proximas horas), este tipo de operacion "en el anden auxiliar" es posible. Otro problema es que, como dicen en el articulo, "there isn't the safety net", aunque en el ejemplo nuestro sí que la hay, en el sentido de que todo esta en algun log y puede repetirse si ha fallado.
Otro uso creativo que le veo, mas que la replicacion síncrona, es la replicacion todos a todos. Sin pasarse, digamos para tres nodos: En cada nodo corren dos mysqld en federacion, dbN y dbN', los dos con el "log-slave-updates" quitado, y cada uno se hace esclavo de uno de los otros dos nodos. Resultado: tres nodos replicados sin que el bloqueo de uno fastidie a los otros dos. ¿alguien tiene esto montado? ¿le funciona?